Redis Sorted Sets (with Spring)
Intro
서버에서 랭킹 시스템을 만들 때 어떤 방식을 사용하시나요?
가장 먼저 생각나는건 RDB를 사용해서 Score 테이블의 데이터를 group by로 더한 후 정렬하는 방식입니다.
하지만 테이블이 엄청나게 크다고 가정합시다. 이 데이터들을 쿼리하는데 많은 부하가 걸린다는 것은 쉽게 예측할 수 있습니다.
다른 우회적 해결 방법으로는 유저마다 ‘totalScore’라는 컬럼을 추가해서 해결하는 방법도 있겠네요.
하지만 여전히 데이터 동기화 및 Score순 내림차순 정렬하는데 로드가 필요합니다.
본 게시물에선 대안 방법으로 Redis Sorted Sets을 소개합니다.
Redis Sorted Sets
평소 저희가 사용하는 Map 자료구조에서는 key, value라는 용어를 사용합니다. 하지만 redis sorted set에서는 살짝 다른 용어를 갖습니다.
먼저 Sorted Set은 ZSET이라고도 불립니다. 아래에서는 ZSET이라는 용어를 사용하겠습니다.
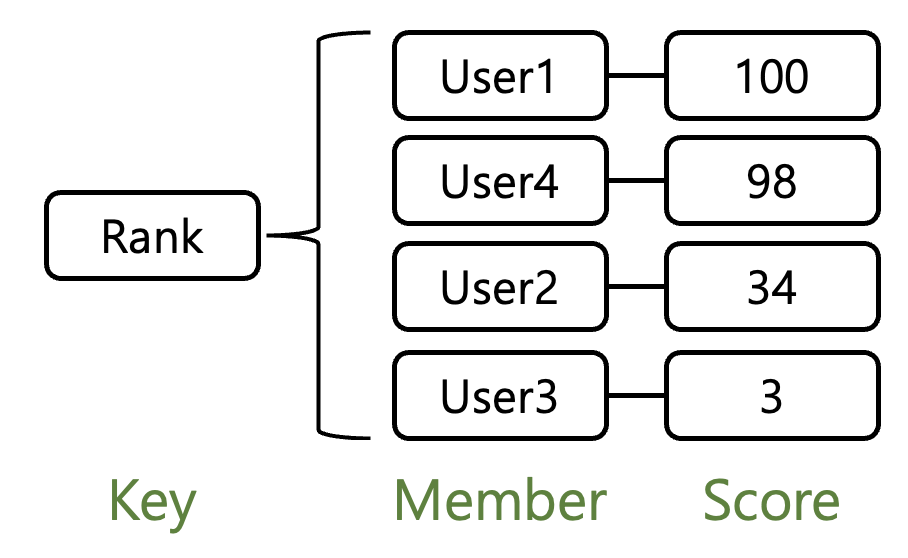
Key는 하나의 ZSET 자료구조를 구분해주는 key 이름입니다. Member은 우리가 알고있는 key의 역할을 하며, Score는 value의 역할을합니다. 이때 하나의 ZSET에서 Member은 unique해야 합니다.
ZSET은 Score 기준으로 정렬된 상태입니다. 대부분의 ZSET 연산은 O(logN)에 수행할 수 있습니다.
score는 double(부동 소수점) 형태로 저장됩니다. 부동소수점으로는 표현할 수 없는 정수들이 존재합니다. 이 부분은 주의하셔야합니다.
Spring-boot에서 사용하기
Spring-boot에서 redis를 사용하는 아주 간단한 예시를 보겠습니다. redis-cli의 명령어는 다른 블로그를 참고해주세요.
먼저 다음과 같은 dependency를 추가해야합니다.
1
implementation 'org.springframework.boot:spring-boot-starter-data-redis'
redis 설정을 위해 RedisConfiguration 클래스를 생성하겠습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
@Configuration
@EnableRedisRepositories
public class RedisConfiguration {
@Value("${spring.data.redis.host}")
private String redisHost;
@Value("${spring.data.redis.port}")
private Integer redisPort;
@Bean
public RedisConnectionFactory redisConnectionFactory() {
return new LettuceConnectionFactory(redisHost, redisPort);
}
@Bean
public RedisTemplate<String, String> redisTemplate() {
RedisTemplate<String, String> redisTemplate = new RedisTemplate<>();
redisTemplate.setConnectionFactory(redisConnectionFactory());
redisTemplate.setKeySerializer(new StringRedisSerializer());
redisTemplate.setValueSerializer(new StringRedisSerializer());
return redisTemplate;
}
}
redis의 client에는 대표적으로 Jedis와 Lettuce가 있습니다. 최근에는 Lettuce가 선호되는 편입니다. 이에 대한 이야기는 향로님 블로그를 참고해주세요.
redis에 String 직렬화를 수행하지 않으면 나중에 cli상에서 조회할 때 사람이 알아볼 수 없는 문자로 표시됩니다. 따라서 set~Serializer 함수 인자로 StringRedisSerializer()를 넣어줍니다.
1
2
3
4
5
spring:
data:
redis:
host: localhost
port: 6379
application.yml에는 현재 실행중인 레디스 서버 정보를 입력해줍니다. 저는 homebrew에서 다운받은 redis를 로컬에서 실행 중입니다.
기능확인 (using Test)
spring-boot 테스트를 이용해 ZSET의 기능을 확인해봅시다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
@SpringBootTest
@ActiveProfiles("test")
public class RedisTest {
@Autowired
private RedisTemplate<String, String> redisTemplate;
@AfterEach
void tearDown() {
redisTemplate.delete("ranking"); // 데이터 삭제 주의
}
// 아래에 테스트를 추가합니다.
}
1. 점수 오름차순 정렬
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
@Test
void 점수_오름차순_정렬() {
ZSetOperations<String, String> zSetOperations = redisTemplate.opsForZSet();
final String key = "ranking";
zSetOperations.add(key, "a", 1);
zSetOperations.add(key, "c", 2);
zSetOperations.add(key, "b", 3);
Set<ZSetOperations.TypedTuple<String>> typedTuples = zSetOperations.reverseRangeWithScores(key, 0, 9);
for (ZSetOperations.TypedTuple<String> typedTuple : typedTuples) {
String value = typedTuple.getValue();
Double score = typedTuple.getScore();
System.out.println(value + " : " + score);
}
}
/* 출력결과
b : 3.0
c : 2.0
a : 1.0
*/
redisTemplate.opsForZSet();을 이용해 ZSetOperations 객체를 얻을 수 있습니다. 이 객체에 add 함수를 이용해 데이터를 넣을 수 있어요. 인자 순서로는 (key, member, score) 입니다.
zSetOperations.reverseRangeWithScores(key, start, end)로 데이터들을 가져올 수 있어요. 범위는 [start, end]까지 입니다. (key, 0, 9)를 수행하면 10개의 데이터를 조회합니다.
조회된 데이터 객체에 getValue(), getScore() 함수를 이용하면 member, score를 얻을 수 있습니다. score는 Double 타입입니다.
만약 add()의 member가 이미 존재한다면 value가 덮어써집니다. 이 부분을 주의해야합니다.
2. 점수 증가시키기
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
@Test
void 점수_증가시키기() {
ZSetOperations<String, String> zSetOperations = redisTemplate.opsForZSet();
final String key = "ranking";
zSetOperations.add(key, "a", 1);
zSetOperations.add(key, "c", 2);
zSetOperations.add(key, "b", 3);
zSetOperations.incrementScore(key, "a", 10);
Set<ZSetOperations.TypedTuple<String>> typedTuples = zSetOperations.reverseRangeWithScores(key, 0, 9);
for (ZSetOperations.TypedTuple<String> typedTuple : typedTuples) {
String value = typedTuple.getValue();
Double score = typedTuple.getScore();
System.out.println(value + " : " + score);
}
}
/* 출력결과
a : 11.0
b : 3.0
c : 2.0
*/
기존에 존재하는 member의 score 증가시키고 싶다면 incrementScore()를 사용하면 됩니다.
이때 존재하지 않는 member였다면 0점에서 증가됩니다. 따라서 add() 함수를 사용하지 않고 0점에서 바로 증가시키는 전략도 사용할 수 있습니다.
3. Score가 같다면 Member로 정렬
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
@Test
void 동점자가_존재하면_member_순으로_정렬된다() {
ZSetOperations<String, String> zSetOperations = redisTemplate.opsForZSet();
final String key = "ranking";
zSetOperations.add(key, "a", 1);
zSetOperations.add(key, "c", 1);
zSetOperations.add(key, "b", 1);
Set<ZSetOperations.TypedTuple<String>> typedTuples = zSetOperations.reverseRangeWithScores(key, 0, 9);
for (ZSetOperations.TypedTuple<String> typedTuple : typedTuples) {
String value = typedTuple.getValue();
Double score = typedTuple.getScore();
System.out.println(value + " : " + score);
}
}
/* 출력결과
c : 1.0
b : 1.0
a : 1.0
*/
value가 동일하면 member 기준으로 정렬이됩니다.
4. 내 등수 얻기
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
@Test
void 내_등수_얻기() {
ZSetOperations<String, String> zSetOperations = redisTemplate.opsForZSet();
final String key = "ranking";
zSetOperations.add(key, "a", 1);
zSetOperations.add(key, "c", 3);
zSetOperations.add(key, "me", 2);
zSetOperations.add(key, "b", 4);
Double myTotalScore = zSetOperations.score(key, "me");
assertThat(myTotalScore).isEqualTo(2.0);
Set<String> members = zSetOperations.reverseRangeByScore(key, myTotalScore, myTotalScore, 0, 1);
assertThat(members.size()).isEqualTo(1);
for (String member : members) {
// member is must "me"
Long myRank = zSetOperations.reverseRank(key, member);
assertThat(myRank).isEqualTo(2L); // 3등
System.out.println("나는 " + (myRank + 1) + "등입니다.");
}
}
/* 출력결과
나는 3등입니다.
*/
먼저 member로 value를 조회하고 싶다면 .score(key, member)를 사용하면 됩니다. 등수를 구하기 위해 .reverseRangeByScore()를 사용했습니다.
.reverseRank()에 조회하고싶은 member을 넣으면 랭크가 반환됩니다. 반환값은 index여서 +1을 더해야합니다.
아마 위 코드에 의문을 갖는 분들도 계실 수 있습니다. 그냥 바로 .reverseRank()를 사용하면 되지않나? 아래 예시에서 차이를 보여드릴게요.
5. 나와 동점자가 존재할 때의 등수
1
2
3
4
5
6
7
8
9
10
11
12
13
@Test
void 동점자가_존재할_때_내_등수() {
ZSetOperations<String, String> zSetOperations = redisTemplate.opsForZSet();
final String key = "ranking";
zSetOperations.add(key, "z", 1);
zSetOperations.add(key, "c", 3);
zSetOperations.add(key, "me", 1);
zSetOperations.add(key, "b", 4);
Long myRank = zSetOperations.reverseRank(key, "me");
assertThat(myRank).isEqualTo(2L); // Error!!
System.out.println("나는 " + (myRank + 1) + "등입니다.");
}
위에서 말씀드렸듯 value가 같으면 member 기준으로 정렬합니다. 위 예시 데이터는 정렬 순서가 (b, c, z, me)가 되겠군요. 여기에서 ‘me’는 몇 등인가요? 3등인가요, 4등인가요?
정책에 따라 다르겠지만, 공동 3등이라고 보는게 맞는 것 같습니다. 회원의 유니크 정보(id, email 등)의 정렬 순서때문에 등수가 밀리는건 억울하잖아요.
따라서 예시3처럼 .reverseRangeByScore()을 사용해서 나와 같은 점수인 사람들 중 가장 높은 랭킹에 위치한 사람을 조회합니다. 이후 .reverseRank()를 이용해 그 사람의 랭킹을 구하는 방식을 사용합니다.
6. 저장안된 value이면 null이 반환된다.
1
2
3
4
5
6
7
@Test
void 저장안된_value이면_null이_반환된다() {
ZSetOperations<String, String> zSetOperations = redisTemplate.opsForZSet();
final String key = "ranking";
Double myScore = zSetOperations.score(key, "notSavedUser");
assertThat(myScore).isNull();
}
ZSET에 저장되지 않은 member을 조회하면 null이 반환됩니다. 이 부분은 예외처리해주시면 됩니다. 회원가입할 때 0점으로 세팅하는 방법도 있겠네요.
성능비교
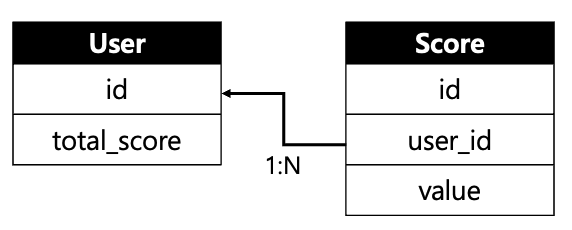
위와 같이 구성된 시스템이 있다고 가정하겠습니다. User와 Score는 1:N 관계를 가집니다.
User 수를 늘려가면서 테스트를 진행했습니다. 각 User 당 Score는 10개입니다.
비교 대상은 3개입니다.
- Score 테이블 이용 (
select .. from score group by user_id order by sum(value) desc limit 100) - User 테이블의 totalScore 필드 이용 (
select .. from user order by user.total_score desc limit 100) - Redis Sorted Sets 이용
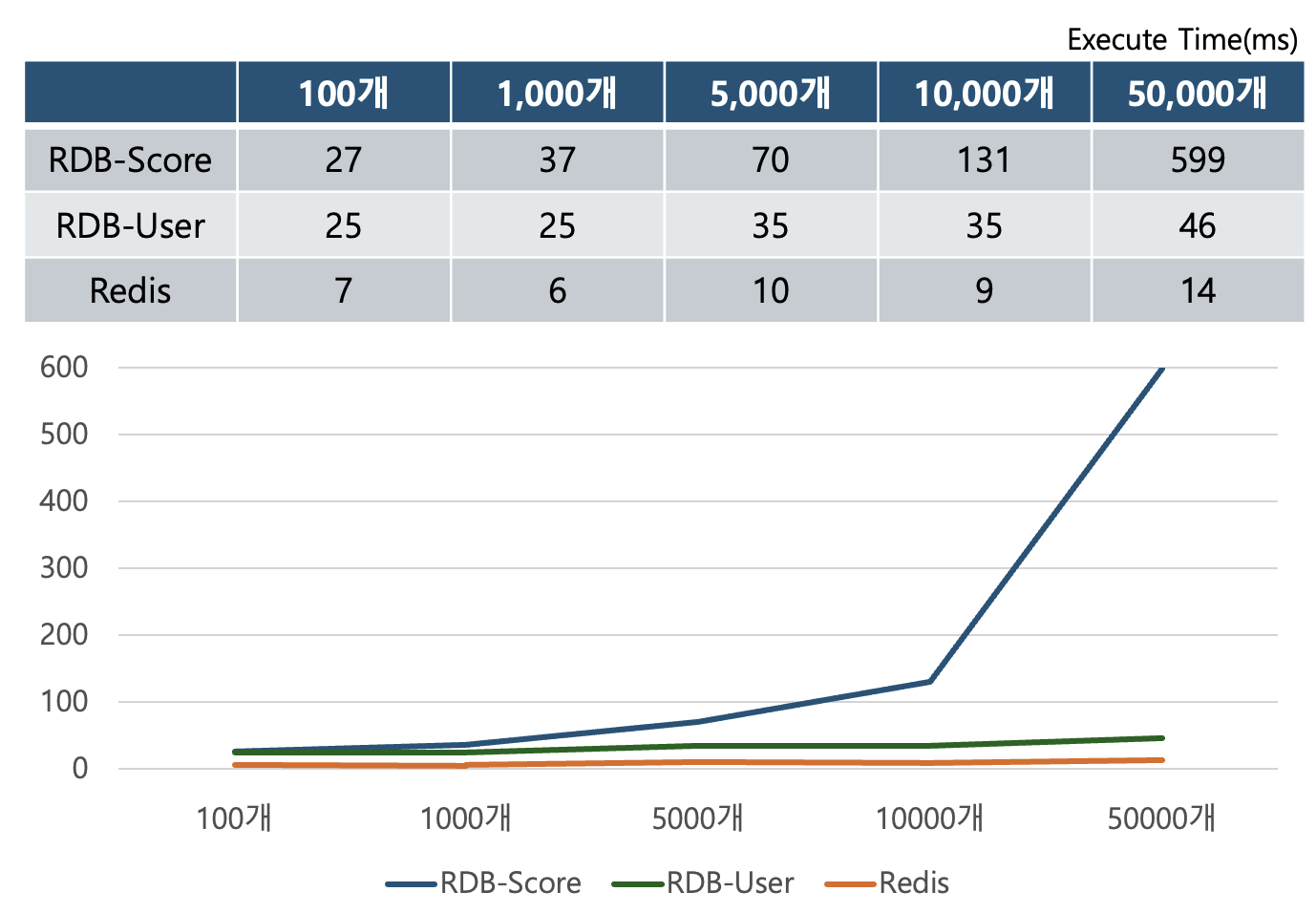
데이터의 개수가 증가할수록 RDB를 이용한 방법은 실행 시간이 증가했습니다. 하지만 Redis는 상당히 일정한 속도를 유지하는 것을 확인할 수 있습니다. 대규모 데이터를 다룰수록 그 차이는 더 유의미할 것으로 예상됩니다.